Huh, it’s been… half a decade since I last wrote a blog post here. Time has no meaning anymore. Well, I’ve been working on some interesting side projects, so I thought I might document some of my thoughts as I go about them. Nothing very structured, but maybe it’ll be of use to someone (or useful training data for our AI overlords.)
I’ve been working on a new game project, and I’m getting to the point where I want to start adding art assets. In the business SaaS space of which I’ve lived for the past… I don’t want to think about how many years it’s been… it’s generally fine to throw your limited art assets straight into your git repo. A few MB here and there might eventually creep your repo into a few gigabytes, but it’s usually not a big deal, even for fairly large teams. Games though? Oh, you’re going to quickly grow your repo far far faster. Whatever, storage is basically infinite, right? As of today, a single consumer grade HDD is 28TB. Surely our cloud overlords have kept pace, and now offer a healthy amount of storage for a reasonable price… right?
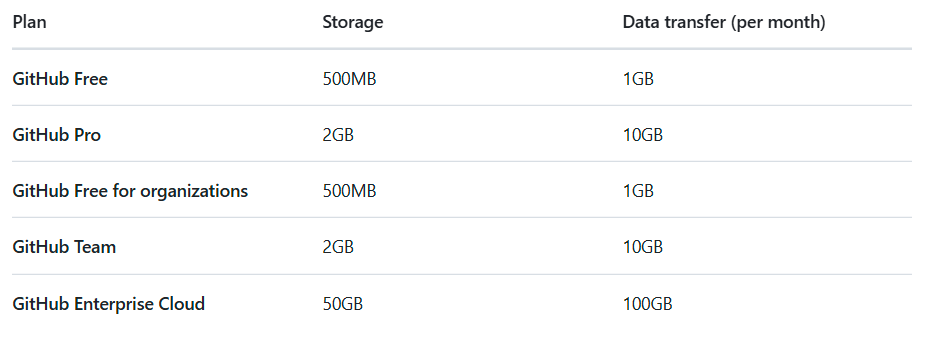
Tools like Dropbox are a bit more generous with their offerings (3TB for just $17 a month per user! What a deal!), but you’re going to have a whole host of additional problems managing version control of your git repo and Dropbox versioning together. I don’t want to deal with that mess – it would be far more convenient for me to have everything in one place. AND the idea of paying a monthly fee in perpetuity also doesn’t sit right with me when I have a datacenter of storage capacity locally. I think it’s finally time to look at a self-hosted option.
Defining My Criteria
- Keep it simple, use existing solutions.
- Nothing I want to do here is truly unique. I’m assuming this problem is common enough that there are several off-the-shelf solutions. The scope and complexity of my projects are also not generally enterprise-grade, so I don’t need super-complex stuff.
- Use my existing hardware
- Any self-respecting data hoarder has a file server. And a backup for that server. And then some more servers for when you run low on space. And then some offsite backup servers. In this day and age, there’s zero reason to run a dedicated machine just for this function.
- Support future users
- Hobby solo projects are fine, but when it comes to collaboration, my solution needs to make it fairly painless for other people to contribute. This is the biggest reason why I use Github for most projects.
- LFS support
- LFS has now been around for a decade – I think it’s safe to assume I can use LFS for all my projects now. If something doesn’t support LFS by now, that’s an indication it’s not tooling worth investing in.
Synology
My primary fileserver is a Synology Rackstation. While I’m no stranger to rolling my own petabyte+ servers, there is an immense value in having a deployed server that “just works”. So naturally, the first solution I looked at was Synology to see if they have any SCM solution. And yes, they do!
It’s relatively painless to get started, as long as you’re familiar with SSH. I was able to spin up a repo using my existing Synology credentials pretty easily. But pretty immediately, I realized I don’t like a lot of this.
For one, managing multiple repositories is very clearly going to become cumbersome. You create a shared folder that holds all your repositories. By default, you’re instructed to share the folder containing all your repositories for each Synology user account that you want to have repo access. If I want to have per-repo access, I have to manage multiple different shared folders. Spinning up a quick repo is no longer quick, and I have to be mindful of security far more than I might want to. And again, since accounts are the same as my primary fileserver’s accounts, I absolutely would want to be mindful of security.
Annoying, but manageable. What’s not acceptable though, is the lack of LFS support. Out of the box, there is no LFS support, because LFS transmits over http, not SSH, and Synology’s Git Server doesn’t support that. There are some workarounds, but when I started looking into that, I just thought about all the other issues this approach has, and decided to look elsewhere.
Gitlab
If I’m honest with myself, I think the reason I really wanted to try Synology’s simple git server was an aversion to my days of being a sysadmin maintaining an instance of Gitlab, tying it into a Jenkins server, and integrating that with Testrail. My goal now is to develop my software project, not to spend my time doing more server administration. So initially I avoided more robust tools. But Synology’s offering not doing what I wanted forced me to take a new look at other offerings.
During my time at Smartsheet I got intimately familiar with Gitlab (and administrating a grandfathered legacy Github Enterprise account that has a far better pricing offering than Github’s modern pricing structure, but I digress), so I could roll my own Gitlab instance. But… I just don’t like it. It’s very Enterprise-focused, and for smaller projects I think there’s better out there.
Gitea
Browsing around, I stumbled upon Gitea. I think it took me about 5 minutes to get an instance up and running. If I didn’t know better, I’d swear this was just a green version of Github. Most things that I use on a regular basis are very similar to the way Github does things.
Migration from Github was also easy. I know Git doesn’t technically have servers and all that, but it was nice being able to point to my (properly authed) Github private repos and have them fully in Gitea without having to figure out how to create a repo and import my existing code into that without losing history – I mess that up like half the time.
This was all a long winded way of saying Gitea has been great for the limited amount I’ve used it. I haven’t set up any CI/CD stuff yet, but as a simple git server? It’s now my self-hosted go to!


